

本文第一作者刘子铭为新加坡国立大学三年级博士生,本科毕业于北京大学,研究方向为机器学习系统中的并行推理与训练效率优化。通信作者为上海创智学院冯思远老师和新加坡国立大学尤洋老师。共同作者来自于上海奇绩智峰智能科技有限公司,北京基流科技有限公司等。
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家)架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。这一稀疏激活策略使模型能扩展到数万亿参数规模,但也给推理系统带来了新的挑战:
扩展性差:
现有主流 MoE 推理框架大多要求使用大规模同步通信组来部署模型,一次性占用大量 GPU 资源,使弹性资源伸缩变得十分困难。这种粗粒度伸缩方式导致资源供给无法严格按照当前用户流量进行调整,只能按整块单元增加或减少,造成资源浪费。
容错性低:
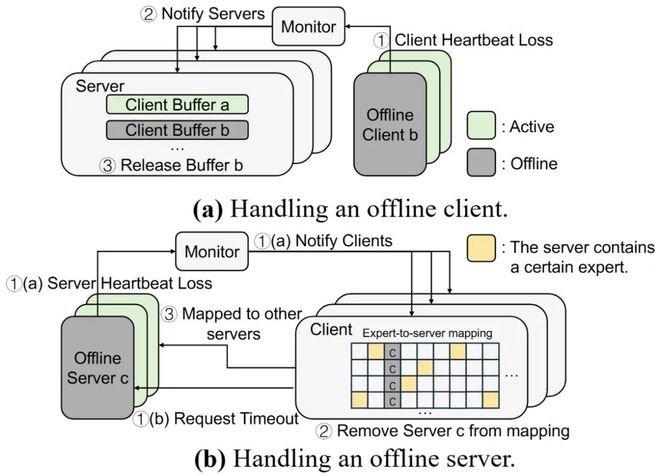
传统 MoE 推理采用全局紧耦合架构,各 GPU 间通过 All-to-All 等大规模集体通信协同工作。在这种高度依赖统一通信组的设计下,任意一个节点故障都可能迫使整个服务集群重启,导致服务中断。也就是说,系统缺乏容错能力,一处故障即全局崩溃。
负载不均:
MoE 中的专家调用是动态稀疏的,哪个专家被激活取决于输入内容,在不同的工作负载下被激活的分布有很大区别。固定的专家映射和资源分配策略难以适应这种波动。某些专家所在 GPU 因频繁命中而过载,而其他专家节点长期闲置,造成资源利用低下。
通过观察,作者发现这些问题其实有共同的根本原因:整个系统被当作一个庞大的 “有状态整体” 去管理。事实上,专家层本质上是无状态的,它对输入执行纯函数计算,不依赖历史上下文。作者利用这一特性,将专家层的计算抽象为独立的无状态服务,与维护 KV 缓存的 Attention 前端解耦部署。尽管近期也有研究尝试解耦 Attention 层与专家层、按不同组件拆分部署,但仍未根本解决伸缩僵化、大规模容错等问题。为此,本文作者提出了一种全新的 MoE 模型推理系统 ——Expert-as-a-Service (EaaS),旨在通过架构层面的创新来提升大规模 MoE 推理的效率、扩展性和鲁棒性。

方法
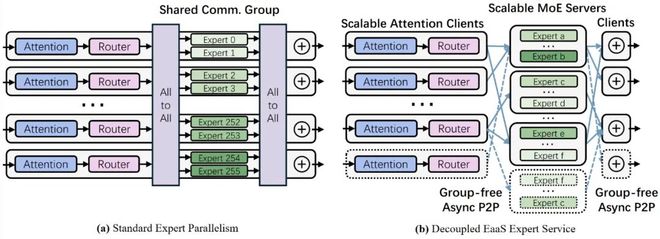
EaaS的 “专家即服务” 的架构转变,使 MoE 推理能够像微服务一样灵活调度。在这一前提下,作者对系统进行了如下设计:
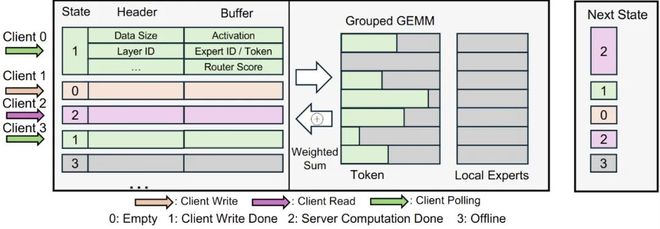
EaaS 专家服务器的动态批处理机制。
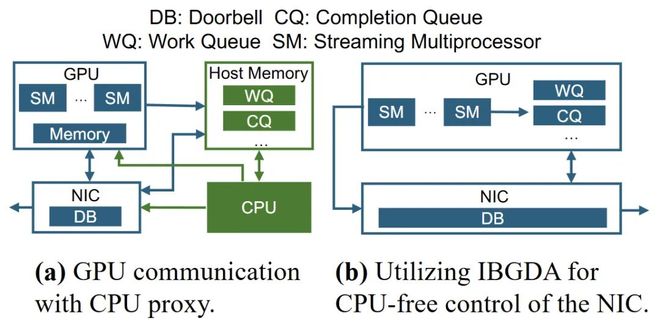
EaaS 利用 InfiniBand GPUDirect Async (IBGDA) 来实现低通信延迟,并通过完全 CUDA graph 捕获来最小化内核启动开销,从而实现无 CPU 控制的通信。
实验
论文通过一系列大规模实验,利用端到端的 benchmark 对比了 EaaS 与当前主流 MoE 推理方案(如 SGLang + DeepEP、vLLM + DeepEP 以及 SGLang + TP 等组合)的性能,在扩展性和容错等方面展现出 EaaS 的优势。
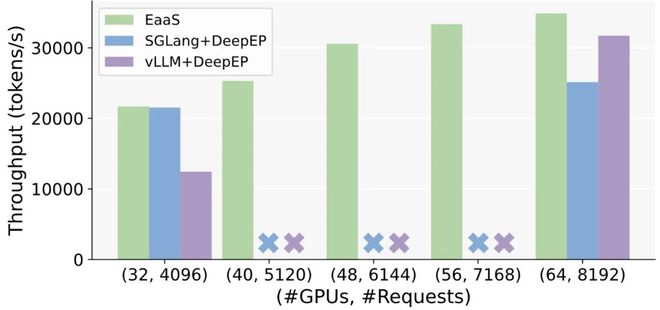
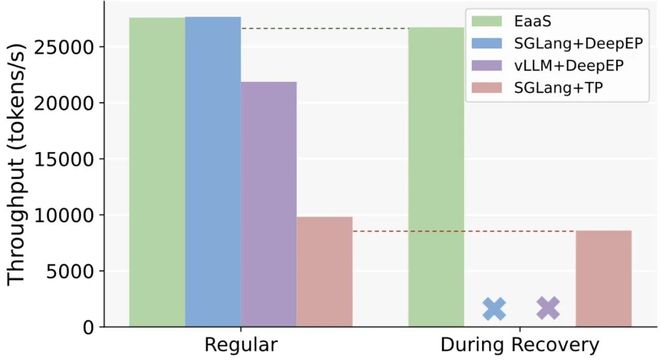
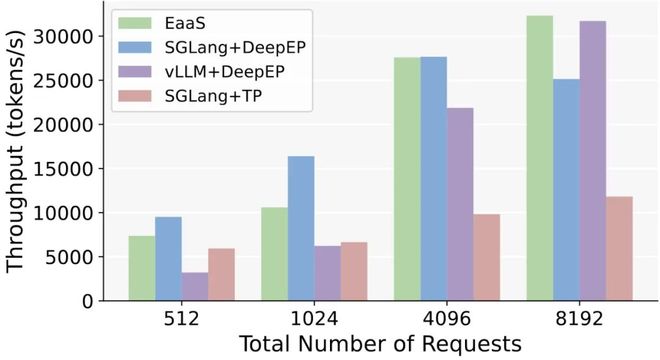
1 对 3 往返通信平均延迟
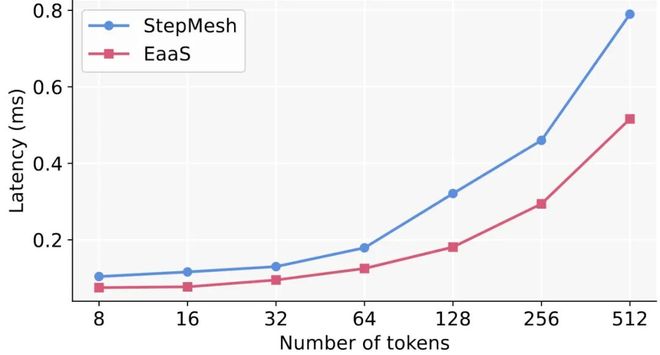
2 对 2 往返通信平均延迟
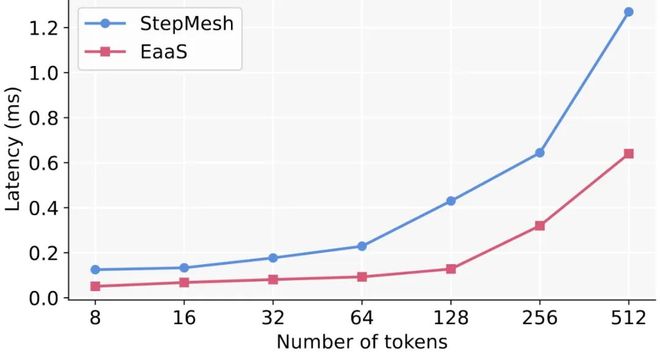
除此以外,作者也将 EaaS 的通信库与当前开源的 Step3 中 StepMesh 使用的通信库进行了 torch 侧调用从端到端的延迟比较,并发现在对称与非对称的场景下,EaaS 的通信库通过 IBGDA 本身的高效通信模式与仅 CPU-free 的结构支持的 CUDA graph 带来的 kernel launch 开销的 overlap,最多将延迟降低了 49.6%。
总结
面向未来,EaaS 展现出在云端大模型推理和模型即服务(MaaS)等场景中的巨大潜力。其细粒度的资源调配能力意味着云服务提供商可以根据实时负载弹性地调整 MoE 模型的算力分配,从而以更低的成本提供稳定可靠的模型推理服务。这种按需伸缩、平滑容错的设计非常契合云计算环境下的多租户和持续交付需求。另一方面,EaaS 的服务化架构具有良好的可运营和可演化特性:模块化的专家服务便于独立升级和维护,通信调度组件也可以逐步优化迭代,从而使整套系统能够随着模型规模和应用需求的变化不断演进。

