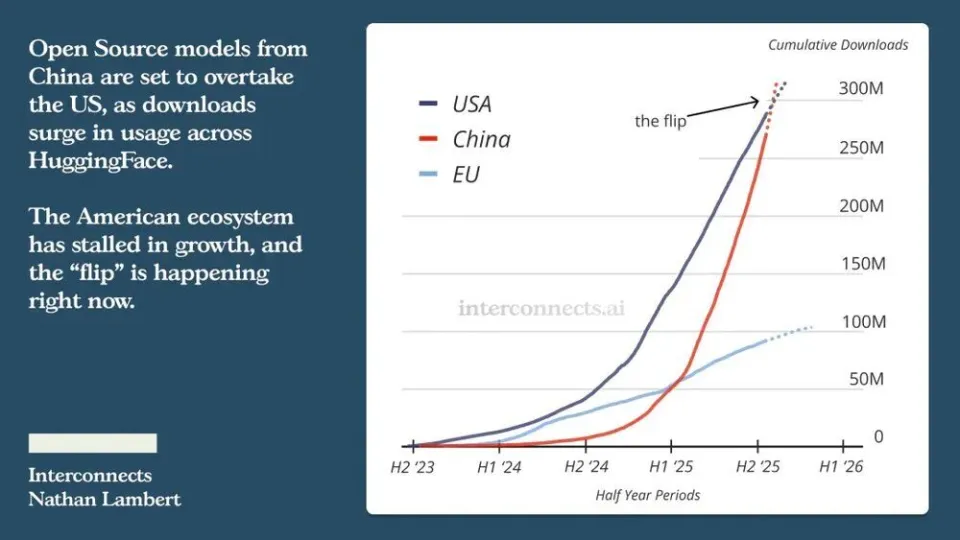
最近,Interconnects.ai 的一份报告,像在科技圈丢下一枚炸弹:截至 2025 年 8 月,中国开源大模型在 HuggingFace 上的下载量正快速赶上美国,几乎已经超越了。

美国这2年在开源模型上的领先地位,似乎正在被反超。在鲸哥看来,这不只是一个数据酷炫,下载量说明大家真的在用,证明我们在模型质量、生态建设等方面都实现了反超。
很多人不理解意义,简单说在移动互联网时代,很多人都用的是安卓手机,开源的安卓统治了移动操作系统的过半壁江山。AGI时代,Meta也高举开源大模型的大旗,很多国外企业采用Llama作为AI 引擎,输出AI的消费级服务。
Llama差点成为新时代的安卓,现在 DeepSeek、Qwen等模型,改变了这一现状。
国产大模型的高光时刻
具体说,是Interconnects.ai 在《ATOM Project》这份报告里,统计了 Meta、Google、Mistral AI、Microsoft、Alibaba Qwen 和 DeepSeek 等几家主要大模型开放者,从它们在 HuggingFace 上的下载量和派生(fine‑tune/派生模型)的情况做了归类。报告里几个关键点:
到 2025 年 8 月,美国领先的开源模型(主要是 Llama / Meta 系列)与中国领先的开源模型下载总量都在约 3 亿次(~300M 次下载) 左右。两边差距已经非常小。
中国模型下载量的增长速度明显快于美国模型。每个月新下载量/新增派生模型的比例,中国那边涨得更陡。
在派生/fine‑tune 模型数量上,美国的留存领头优势在减弱。以前美国模型(主要是 Llama 系列)派生模型占比非常高,但到现在,中国模型(比如 Qwen 系列)一个月的新派生模型中可能占到 40% 以上。美国 Llama 系列的派生比例从巅峰时的近 50% 下滑到大约 15%。
再看国产模型的一些动静:
DeepSeek 的 V3 与 R1 模型,自从发布后震动不小。DeepSeek‑V3 发布在 2024 年底/2025 年初,其在数学、编码任务上的表现被业界认为“性价比高 + 推理快 +成本比惊人”。
紧接着,阿里在 2025 年春节发布了 Qwen 2.5‑Max。几个月后,阿里又发布了 Qwen 3 系列,带 hybrid reasoning(混合推理)能力。
Qwen3包含235B和30B两种MoE架构及6个Dense模型,覆盖6B-232B的多种尺寸的8款系列模型。阿里的Qwen系列更新速度和更新范围在全球都无出其右。
不只是DeepSeek和Qwen在充当主力军,混元开放从 0.5B 到7B 的小尺寸模型,支持终端与低功耗场景落地。
Kimi K2 是一个 1T 参数总量、32B 激活参数的 MoE 模型,对 Agent 与 coding 任务友好,支持 128K 上下文,开源且免费商用。
GLM-4.5 融合了推理、代码与智能体能力,是国产开源模型中的新标杆,在多个 benchmark 上为开源模型中表现最优,参数效率与成本效益显著提升。
所以「下载量几乎赶上 + 新模型速度 +派生/fine‑tune 模型数目增多」这些都指向了一个拐点:中国开源大模型生态不再是追随者,而是正式进入高速对抗+超越可能的阶段。
国外开源为何落后?
美国这边落后的原因,不是因为人物不努力,而是结构 +生态 +方向 +部署门槛几个地方被拉开了差距。Llama 4 是一个重要节点,可以重点说下。
Meta 在 2025 年发布了 Llama 4 家族(包括 Maverick、Scout 等版本),这个赶工版本出现了很多问题:
1.过载现象严重,应试的产物
有传言Llama 4 在后训练阶段中,将多个benchmark测试集混入训练数据。这让模型的测试成绩出众,但在泛化任务中表现差强人意。实测很多任务的表现还不如GPT-4o。
2.派生 /开源自由度下降
虽然 Llama4 是开源权重模型(open‑weight 模型家族),但在派生(fine‑tune/第三方修改)社区里的活力相比之前有所下降。Interconnects 报告里提到,美国模型(Llama 系列)派生模型的比例从 2024 年底约 50% 高峰降到现在约 15%。意味着很多用户/开发者在下载之后,不是“继续改造/训练/fine‑tune”的机会变少了。
3.成本与部署门槛太高
DeepSeek 和 Qwen 在“低成本推理”“轻量版本 /蒸馏版/distill/量化支持”上动作快,用 GPU/硬件要求稍低的版本可用性更高。Llama4 在最强的版本可能需要更高算力/内存/成本,这在很多中小企业/开发者里是门槛。
而GPT和Grok开源速度又很慢,难以扛起国外的开源大旗。
OpenAI 在 2025 年 8 月 6 日推出自 GPT-2 以来的首批开源权重语言模型 gpt-oss-120b 与 gpt-oss-20b,性能堪比 o4-mini 和 o3-mini,可在高端笔记本和手机上运行。
不过,OpenAI 的主流模型如 GPT-4o、GPT-5 等仍然是闭源的。
8 月 24 日,xAI 开源了 Grok-2。Grok-2 在编码、复杂问题和数学方面表现出色,还能生图识图,性能比肩当时的 GPT-4o。不过,Grok-2 的开源协议较为严苛,xAI 允许非商业与合规商业使用,但禁止用其训练其他基础模型,仅当关联公司年收入低于一百万美元时,才可用于商业用途,超过此门槛的商业用途需获得 xAI 的单独许可。
xAI 表示 Grok-3 将在 Grok-2 开源大概 6 个月内开源。
现在美国开源的大旗,已经看不到一个实力选手了。
开源未来之路探索
最核心的原因,是Meta的Llama4 发布的口碑,确实影响了其行业认可度。
尤其Llama4 虽然支持多模态,但在OCR/图像 + 文本混合应用等细节优化,以及成本/延迟/部署资源要求上,用户反馈并不是每个场景都能“拿来就用”。
最新消息传言,新版本的Llama4X可能转向闭源。
中国的 DeepSeek + Qwen 则多频次推出新版本/升级,以及强劲的中国本土需求 +语言 +多模态场景,让中国模型在下载量+派生+部署效率上增长非常快。
国产开源大模型每隔一段时间就有新版本/新变体/容量/多模态/OCR/混合模态之类的更新。这些频率+迭代让用户/社区“跟得上看到实际进步”的那种信心很强。
比如,最新的 Qwen‑3 系列/Qwen‑Next(有的媒体称之为 下一代 Qwen,或者 Qwen3)被报道拥有混合推理能力(hybrid reasoning),更强的推理 + 对多模态 /实际应用场景的支持。
总结:这不是某一个模型的“反超”,而是生态拐点。
甚至a16z的合伙人Martin Casado说,预计80%的湾区初创公司,都在基于中国开源模型进行开发。
未来几个月/一年里,我们可以重点看三件事:
Qwen‑Next / Qwen3 等下一代模型的正式 benchmark +开源程度如何;
DeepSeek 后续版本将带来多大程度的升级,R2或者V4带来惊喜可期;
HugginFace/ModelScope 等开源模型托管/派生生态是不是继续给中国模型更大的空间增长。
总结来说,中国开源模型的优势不仅是“便宜”或“中文好”,而是“速度 +迭代 +社区生态 +部署门槛低”,这些组合在一起,构成了现在这个拐点。
参考资料:
https://www.interconnects.ai/p/on-chinas-open-source-ai-trajectory