嗨,朋友你好,我是诗康妈咪。
今天去参加了百度举办的2025百度世界大会,在会议上,百度正式发布了他们最新的核武器——文心大模型5.0!
这可不是一次小升级,这次的文心5.0,参数量直接飙到了2.4万亿!
什么概念?就是它“脑子里”的神经元数量多得吓人。百度创始人李彦宏在会上表示:智能本身是最大的应用,而技术迭代速度是唯一护城河。百度会持续投入、研发更前沿的模型,推高智能天花板。
那么,这个“天花板”级别的新模型,到底牛在哪呢?
啥是“原生全模态”?这次真不一样了
这次发布会,你肯定会一直听到一个词:“原生全模态”。
这个词听起来特专业,我来给大家翻译成大白话。
在文心5.0之前,很多号称“多模态”的模型,其实是“拼装”出来的。什么意思呢?
它们可能是先训练一个专门搞文字的(比如GPT),再训练一个专门搞图片的(比如DALL-E),再来个搞音频的……最后把这些“偏科生”用胶水(技术上叫“后期融合”)粘在一起,假装成一个“全科生”。
这样做的缺点很明显,它们对不同模态(文字、图片、视频等)的理解是割裂的,不够深入。
但文心5.0走了一条完全不同的路。
百度的首席技术官王海峰解释说,文心5.0采用的是“原生全模态统一建模技术”。
说白了,就是这个模型从出生第一天(训练刚开始),就不是偏科生。它是把文字、图像、视频、音频这些数据“和在一起”喂给它的。它是在一个统一的架构下,同时学会理解文字、看懂图片、听懂声音的。
这就好比,它不是一个学了八国语言的翻译,它是一个从小就在多语言环境里长大的“混血儿”,天生就能融会贯通。
这种“原生”的好处就是,它的理解和生成是一体化的,各种能力在底层就彻底融合了,不是后期拼凑的。
它到底能干啥?
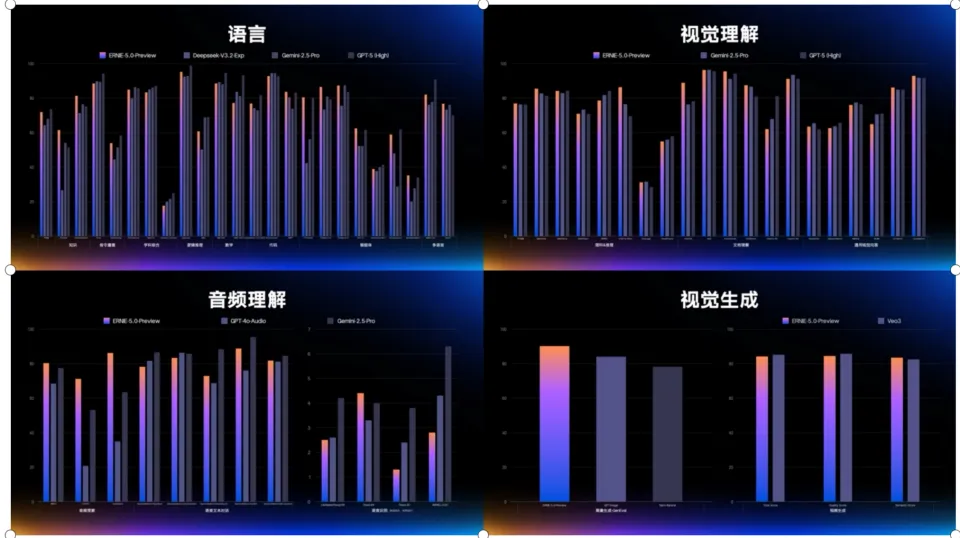
在多模态理解、指令遵循、创意写作、事实性、智能体规划与工具应用等方面表现突出,拥有强大的理解、逻辑、记忆和说服力。在大会现场展示的能力中,有两个特别让我惊喜,分别是“全模态理解”和“全模态生成”
1.超强的“全模态理解”
文心5.0能真正看懂、听懂你给它的所有东西。
例如可以把两段视频发给它,让它分析哪个短视频的营销效果更好。
2.惊艳的“全模态生成”
光能理解还不够,它还能“创造”。
这个视频是在甄嬛传的视频上进行了二创,用武林外传里佟湘玉的风格来说话。
它的排名怎么样
大家最关心的问题来了:它跟全球最顶尖的模型(比如还没发布的GPT-5,或者Gemini的最新版)比怎么样?
百度这次也亮出了“成绩单”。
在一个包含了40多项权威基准的“大考”里:

简单说,文心5.0在“理解”上达到了全球第一梯队,在“生成”上也达到了专业选手的水平。这验证了“原生全模态”这条路的潜力和能力。
而且,就在前几天(11月8日),文心5.0的预览版在LMArena(一个全球大模型的“竞技场”)上,文本任务评测已经拿到了全球并列第二、中国第一的成绩。
2.4万亿参数,会不会“慢死”?
你可能会想,2.4万亿这么庞大的参数,用起来肯定又贵又慢吧?
百度也想到了这一点。他们用了一个“黑科技”叫做“超稀疏混合专家架构”(简称MoE)。
这又是个专业词汇,咱们还用大白话解释:
想象文心5.0是一个拥有2.4万亿名员工的超级大公司。
这个“一小部分”是多少呢?
答案是:激活参数比例低于3%!
用不到3%的“员工”出动,就能达到2.4万亿总员工的智慧水平。这就完美地在“能力超强”和“推理效率高”之间取得了平衡。
我们怎么用上?
说了这么多,怎么才能体验到呢?
百度这次速度很快,发布会刚开完,体验通道就开了:
1.普通用户:现在就可以打开“文心App”,文心大模型5.0的Preview已经同步上线了。2.开发者和企业用户:可以通过“百度千帆大模型平台”,去调用文心5.0的API服务。
总而言之,百度的文心5.0,不仅是在参数规模上又创下了一个恐怖的记录,更重要的是它在“原生全模态”这条技术路线上迈出了一大步。
就像李彦宏说的,智能本身就是最大的应用,而技术迭代的速度,是唯一的“护城河”。
AI的天花板,看来又要被捅破了。
其他好玩的推荐
另外除了文心5.0大模型,我还要介绍两个我觉得非常赞的产品,一个是GenFlow 3.0,可以在百度网盘、百度文库app上使用,不过要升级到最新版本才行。
例如可以在百度网盘上运行这样的任务:
然后我的网盘里就有了这些论文。
另外还有一个工具,就是橙篇,我对它的了解还停留在是生成文章的工具,结果人家已经大大进化了。我在会场,使用橙篇制作了3个谷子并做成了吧唧(好吧,其实这些名词我也是今天才知道的)家里有喜欢动漫的孩子一定喜欢这个工具。
AI世界,真的很有趣,我们一起玩起来呀~